Sorting data in parallel CPU vs GPU - In which we show more graphics
Posted on February 7, 2013 by Paul
The code for this post is on GitHub: https://github.com/sol-prog/Sort_data_parallel/tree/TBB in the TBB branch.
This is a sequel to my last article in which we’ve shown that you can, relatively easily, implement a parallel merge-sort algorithm using only functions from the standard library of a programming language, C++11 in this case. We’ve also compared our implementation with a state of the art sorting function from the CUDA 5.0 SDK thrust::stable_sort.
Following some concerns, raised by a commenter - snk_kid, I’ve made a new set of tests based on a state of the art CPU parallel sorting function from Intel’s TBB. His main these was that my previous comparison between CPU and GPU was misleading, because the use of raw threads in merge-sort is not efficient and, in general, I should refrain myself from writing about this subject unless I use task based parallelism or high level parallel libraries.
The machine used for tests was a consumer laptop with Intel i7 Q740 processor, 16 GB of RAM and an NVIDIA GeForce GT 445M with 3 GB of RAM. Please note that this is not a HPC workstation. If you want to see some results on a modern beast have a look here. Thanks to Andrew Seidl for taking the time to redo the calculations, from our previous article, on his machine, Xeon E5-2630 with 12 threads (HyperThreading enabled) on the CPU side, and an Nvidia Tesla K20c for the GPU.
Fair warning, I’ve modified the code used in the previous article to use a single call to std::inplace_merge, instead of calling two functions std::merge and std::copy. This simple modifications has improved the code performance:
1 ...
2
3 //Merge V[n0:n1] with V[n2:n3]. The result is put back to V[n0:n3]
4 void par_merge(std::vector<double> &V, size_t n0, size_t n1, size_t n2, size_t n3) {
5 std::inplace_merge(std::begin(V) + n0, std::begin(V) + n1, std::begin(V) + n3);
6 }
7
8 ...Including TBB in our code is as simple as:
1 ...
2
3 #include <tbb/parallel_sort.h>
4
5 ...
6
7 // Use Intel's TBB to sort the data on all available CPUs
8 double run_tests_tbb(std::vector<double> &V) {
9 auto start = boost::chrono::steady_clock::now();
10
11 tbb::parallel_sort(std::begin(V), std::end(V));
12
13 auto end = boost::chrono::steady_clock::now();
14
15 return boost::chrono::duration <double, boost::milli> (end - start).count();
16 }
17
18 ...As always, the entire code is available on the Github repository for this article.
Let’s start with a comparison between our parallel merge-sort implementation and parallel_sort from Intel’s TBB. The test data was a random array of double precision numbers with 10 to 10 millions elements. The CPU code was tested in serial (single thread) and parallel (eight threads) mode. We’ve used three C++ compilers: gcc-4.6.3 which is the default compiler on Ubuntu 12.04, gcc-4.7.2 and Clang-3.3svn with libc++. If you are interested in building from sources gcc-4.7.2 and Clang-3.3 you can consult this and this. Each test was repeated one hundred times, the data was averaged and we’ve calculated the standard deviation for each test point.
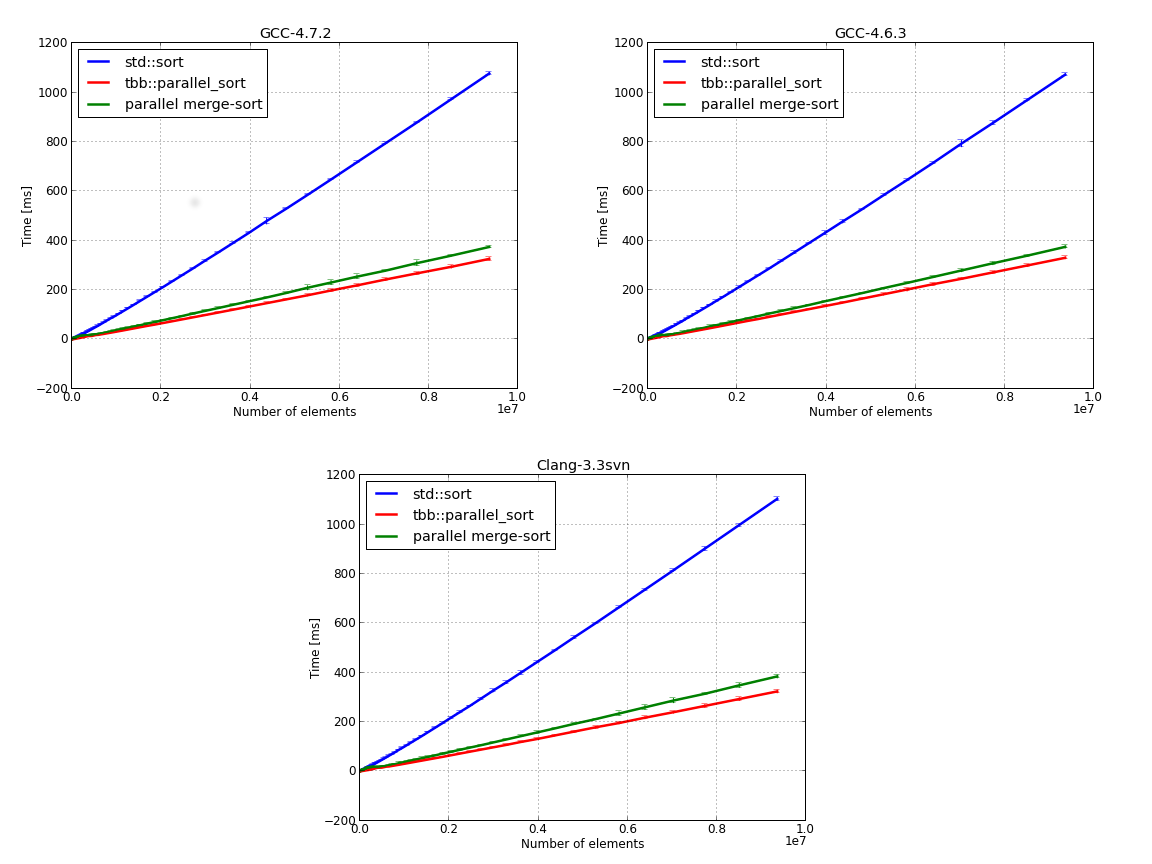
Judging by the above results our parallel merge-sort implementation was not such a bad idea. Obviously, Intel’s TBB is better, after all it is a state of the art parallel library.
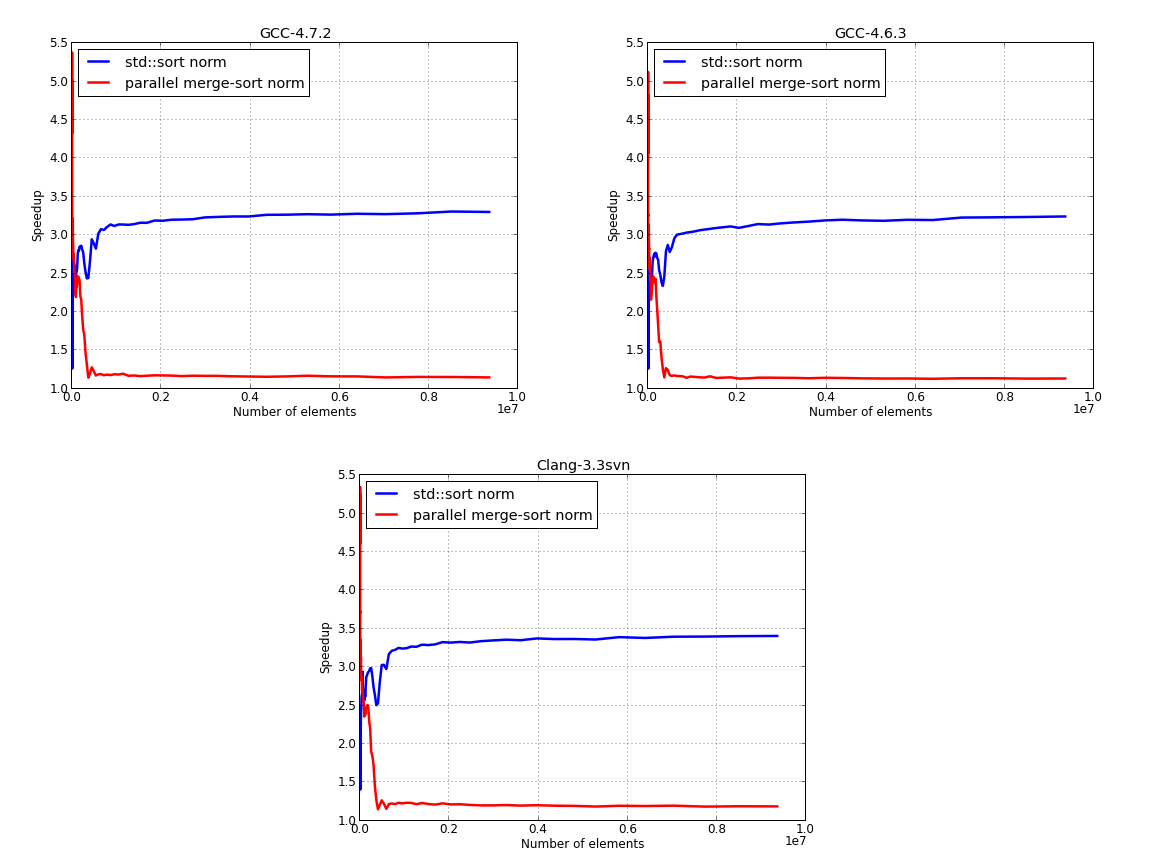
Next figure presents the normalized results, with Intel’s TBB time, for std::sort and our parallel merge-sort. tbb::sort is about 3.x faster than the serial std::sort and 1.x faster than our implementation for large inputs. We could improve the performance of our implementation by using a serial version for small inputs and switching to the parallel version for large data inputs, using some threshold value for making the switch.
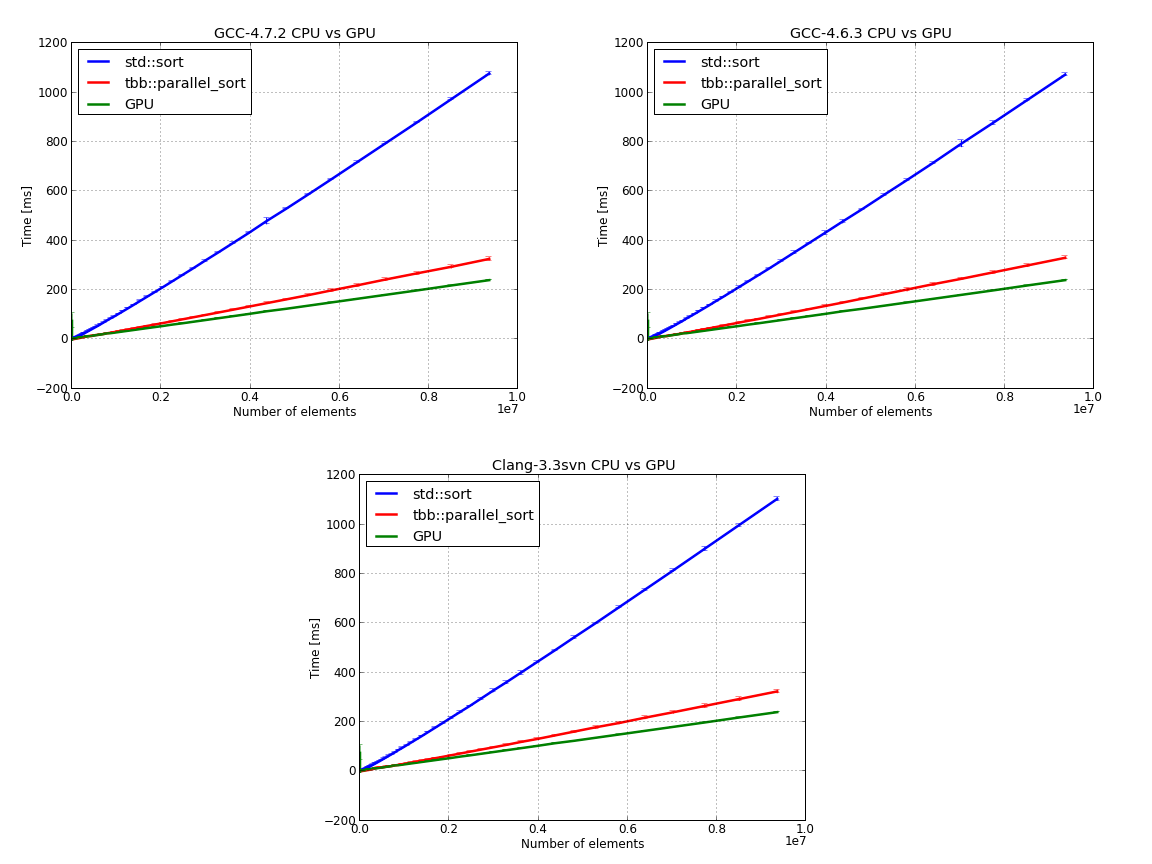
In the next set of figures we compare Intel’s TBB, running on the CPU, with std::sort and thrust::stable_sort from CUDA 5.0:
Here, we’ve used the GPU time to normalize the data for the CPU:
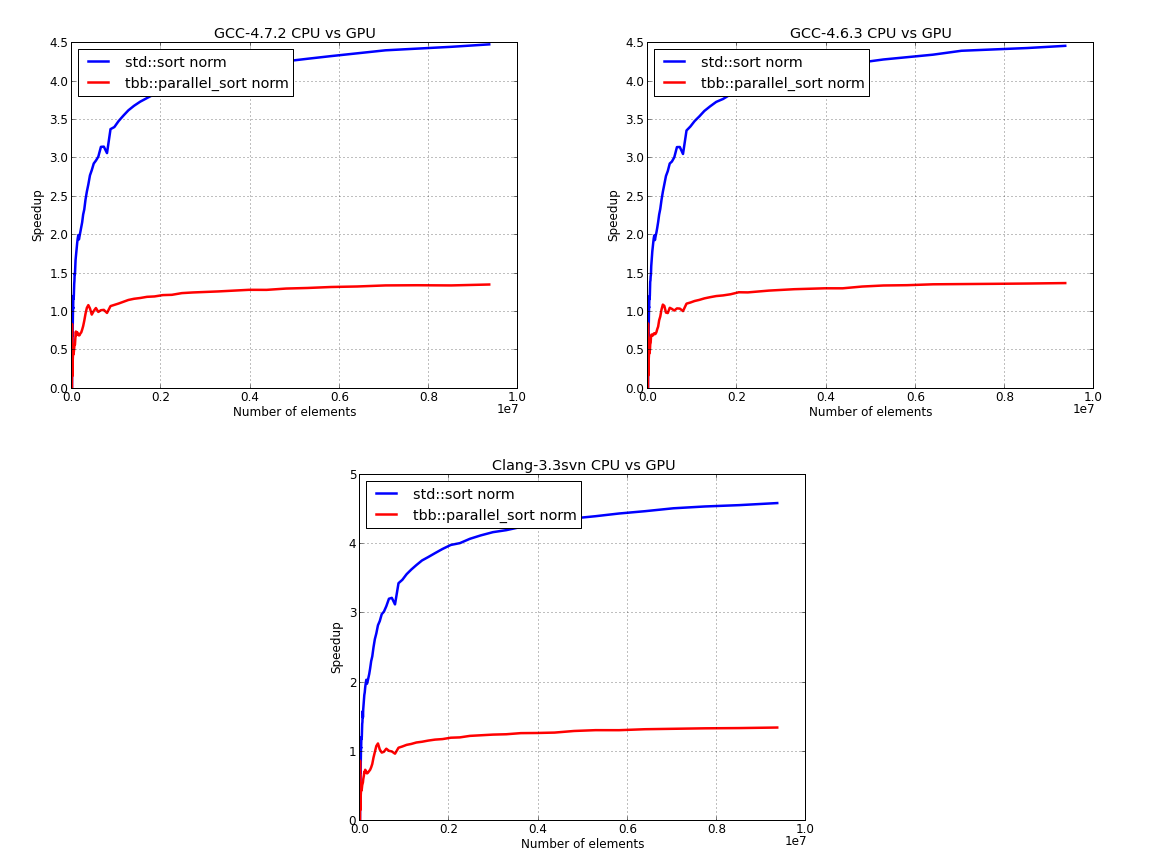
Please note that the above results also contain the cost of transferring data from CPU to GPU and back.
If you are interested in learning more about the C++11 Standard Library, I would recommend reading The C++ Standard Library: A Tutorial and Reference (2nd Edition) by N. M. Josuttis:

If you are interested in learning CUDA, I would recommend reading CUDA Application Design and Development by Rob Farber.
